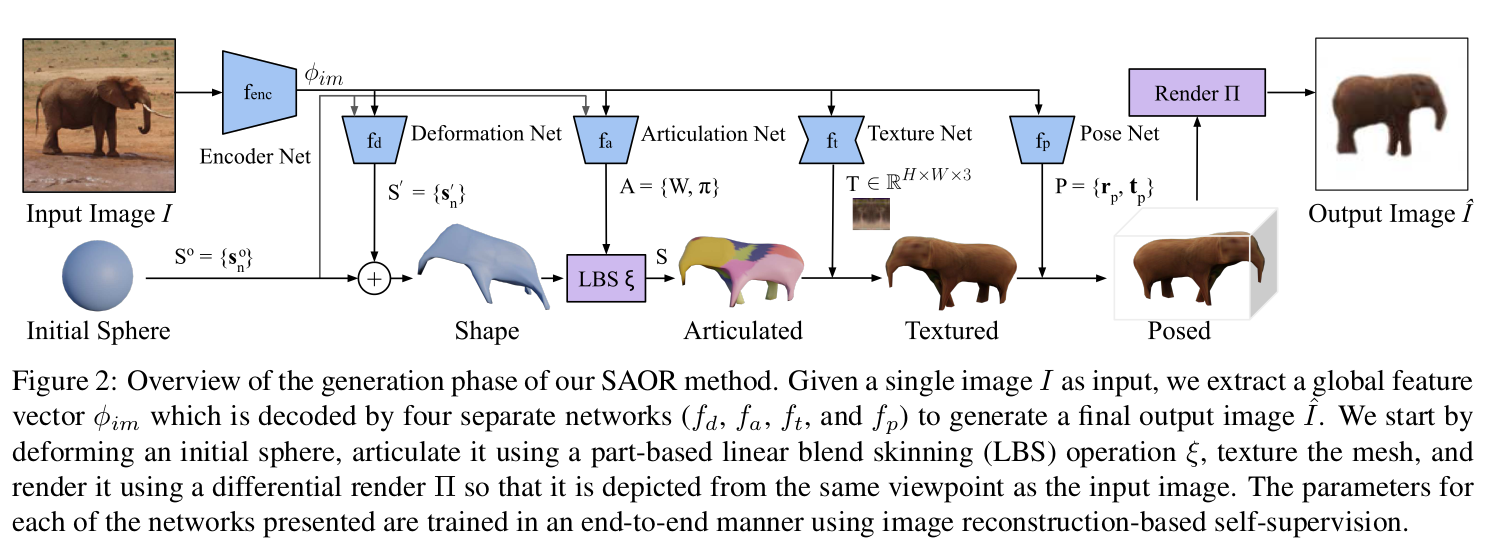
We introduce SAOR, a novel approach for estimating the 3D shape, texture, and viewpoint of an articulated object from a single image captured in the wild.
Unlike prior approaches that rely on pre-defined category-specific 3D templates or tailored 3D skeletons, SAOR learns to articulate shapes from single-view image collections with a skeleton-free part-based model without requiring any 3D object shape priors. Our method only requires estimated object silhouettes and relative depth maps from off-the-shelf pre-trained networks during training.
At inference time, given a single-view image, it efficiently outputs an explicit mesh representation.